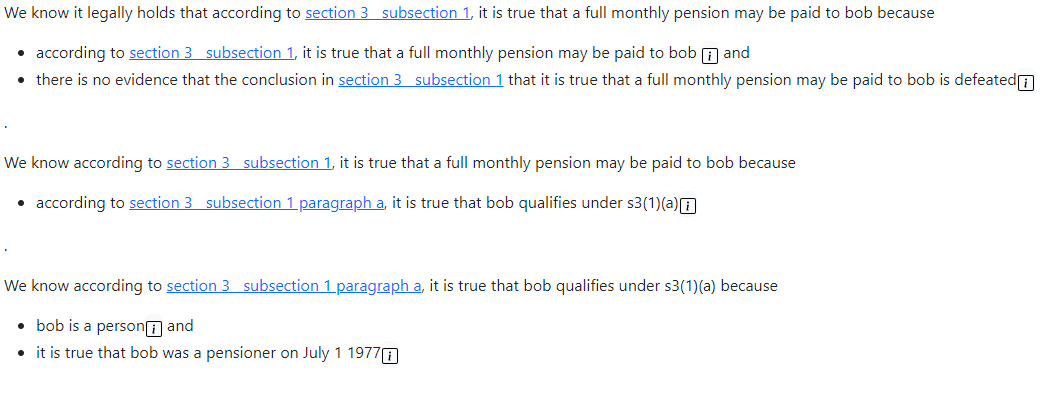
Before and after. Does the paragraph form seem "better"? Took a surprising amount of work, because I had to abandon the NLG being done by the reasoner and write my own version that knows how to deal with nested terms. I'm thinking the new one is probably better for validation, worse for debugging, but I'm not sure.
{kind=link}
{kind=link}
I did an experiment recently where I prompted GPT-3 with a very repetitively phrased set of facts, then had ti produce a text from those facts. This was surprisingly effective for making this sort of thing human friendly without crashing into all the corner cases that old school Prolog NLG does.
In the context of explaining how laws apply to people, I don't think I can ethically pitch the use of technology that doesn't know whether it is correct or not. Not even just for rephrasing, because I can't control how badly the NLG was drafted. And I prefer the first one, too. But then again, I like the raw output from the reasoner, too. So I'm the wrong audience. 😉
Yes, the real crazy thing is how well prompts and tuning works on these LLMs. Tons of potential. And I cannot but imagine that regularity and robustness are major areas of focus right now.
So far, at least in my experiments, the models don't hallucinate facts when all the facts are provided. In this context, it becomes more of a "text humanizer" over a set of assertions.
Improve bias? If I just told you something, work with me and assume it.
But it's not about what you say, it's also about how you said it. If I generated the input text, I would agree. I might even try it for my own encodings where I can control the input text. Because I can avoid doing things that are going to confuse it. But in my larger context, my users are generating the small parts of NLG for each predicate that are being combined to generate explanations, and I can't rely on them not to generate text that will confuse it. Tonnes of potential, I agree, but my tool's virtues are correctness and explanations linked causally to authoritative source material. Natural-sounding text, if it even slightly risks those virtues for a subset of users, is not a virtue. Besides, if my users want ChatGPT to rewrite the explanations they get from my tool, that's why it has an API. :)