An essay about the history of compiler-appeasement languages, meant for discussion.
[meta: I would be glad to move this to another channel or to remove it completely. One aspect of my “work” is to observe. FWIW, I share this...]
Type checkers are helpers for development. Similar to parsing and syntax checkers. Type checkers are - currently - more difficult to write than syntax checkers. There was a time when syntax checking was not well understood and was difficult and was written in an ad-hoc manner. Early FORTRAN had syntax that we would consider weird today. Early FORTRAN did not treat spaces specially and went for the shortest match (I think). For example IF and IFX were both parsed as the beginning of an IF statement. Later, it was discovered that making spaces “special” would help in making parsers and would help in cleaning up silliness like IF and IFX . At the time, the character set consisted of ASCII (well, there was EBCDIC, championed by IBM, but, IBM was hated even more than Microsoft and Apple are hated today, so EBCDIC was mostly avoided by non-IBMers). The fact that ASCII only has 128 characters to choose from (some 32 “unprintables” must be subtracted from this count) made for silly decisions like denoting strings with the same beginning and ending quote (which makes parsing more difficult) and not-allowing spaces to be embedded in names. With Unicode, we have many more choices, but, we remain stuck with decisions made to appease 1950s hardware. Aside: in 2022, we have hardware that can handle vector graphics and overlapping graphical elements, e.g. windows and very-small windows (“buttons”, “widgets”), but, we are stuck with decisions made to appease 1950s hardware. I argue that we should be building languages based on vector graphics instead of non-overlapping characters. SVG is a simple example of something that might work on this front (rectangles, ellipses, lines, text, groups). Aside: “declaration before use” is a result of 1950s thinking (save CPU time by making compilers 1-pass), even though, in 2022, we could easily burn CPU cycles to figure out “declaration after use”. Aside: declaration-checking (before or after use) is only a helper for developers. The machine doesn’t care if you make a typo. “Declaration-checking” is an app to help developers stamp out simple errors (like typos). Demanding that programmers rearrange their code so that the declarations ALL come before the code is compiler-appeasement (based on 1950s hardware).
The best way to write a type checker is to use a Relational Language (like PROLOG, miniKanren, Datalog, etc., etc.). Relational languages are shining examples of languages that don’t appease compilers. In a relational language, you write relations (“truth”) and let the underlying system figure out how to implement the machinery for matching up the relations. Other technologies that bark up this same tree: declarative languages and ML. (Aside: oh my, HTML is a declarative language. But, HTML needs to lean on JavaScript to allow imperative break-outs).
There is no “ideal language”. The notation you use depends on the problem you are trying to solve. A simple example would be the idea of Spreadsheets vs. Lambda Calculus. Accountants and financial analysts like Spreadsheets. Programming rigor analysts like Lambda Calculus. Accountants would not want to use Lambda Calculus and rigor-ists would not want to use Spreadsheets. Another example, closer to my heart, is the difference between using Language Theory to generate parsers and using PEG to generate parsers. Language Theory-based parsers cannot do what PEG-based parsers can do (for example, parse balanced parentheses). Trying to force-fit language theory onto parsing has stagnated the field. Most languages look the same, with minor differences. (Aside: PEG is Parser Theory, not Language Theory, despite the superficial similarities in syntax). The fact that parsing is “difficult” has restricted programmers to using only a small number of programming languages, instead of using a zillion nano-languages and defining their own nano-languages (I call these SCNs (Solution Centric Notations)).
“Dynamic” languages are “good” for fast turnaround on ideas, but are “bad” for producing end-user apps which are cost-optimized. “Static languages” are “good” for Production Engineering apps, but, are “bad” for inventing new products. Trying to force-fit all use-cases into one language results in a watered-down notation which isn’t particularly good for either use-case. (Aside: at the moment, efforts to force-fit all use-cases into one language favour the Production Engineering side over the Design side of things, and, this is what I call “compiler appeasement”. When programmers have to stop and rearrange their inventions to help the compiler figure out how to optimize, they are appeasing the compiler). (Aside: if Physicists ALL engaged in worshipping functional notation, we wouldn’t have Feynman Diagrams, nor Polyani’s “Order Out of Chaos”, etc.).
Barnacles might be invented for helping developers, e.g. type checkers and linters. Twisting a language design to appease only pre-compilation is not OK in my book. At the moment, most of our programming languages are compiler-appeasement languages and insist that developers waste time (and imagination) on dealing with compiler-appeasement and pre-compilation issues, long before the program works.
Barnacle-like pre-compilation was researched in the mid-1900s with work like Fraser/Davidson peephole technologies. This was called RTL and formed the basis of gcc . Cordy’s Orthogonal Code Generator is a generalization of this technique replete with declarative syntax for portability choice-trees (MISTs) and Data Descriptors and Condition Descriptors that improve on the virtual registers used by RTL.
[This essay can be found in github.com/guitarvydas/py0d/issues/2]
I tend to agree with most of this, except that I am not sure I understand your ideas about SVG. In mainstream programming, the ground-truth representation of code is text (a linear stream of characters), and the UI is a slightly rendered version of that text (syntax coloring etc.). I see how SVG could yield better UIs, but it sounds as if you want SVG to become the ground-truth representation of code. If that's the case, I don't see why.
On a different topic, your essay contains the eternal "we are so stuck in the past, we need to move on" thread that comes up frequently here (and elsewhere). What I have yet to see is a realistic proposition for "moving on". If it's "start from scratch", it just won't happen. We are not stuck with 1950s hardware, we have built up an enormous IT edifice starting with 1950s hardware. We are still adding to it, and it has become infrastructure for other human endeavours. It won't go away (except maybe in a major civilization crash).
A realistic scenario for moving on must either start from the present edifice and evolve it into something better, remaining functional along the way, or build a second, disconnected edifice to which the world can slowly migrate as it matures.
Your point regarding declarations reminds me of my archive.org/details/akkartik-2min-2020-06-07
Konrad Hinsen I really agree with this sentiment on the “we are so stuck in the past” thread. It’s a little cliche almost to complain about how software development is such a mess. And not necessarily the most productive mindset.
Kartik Agaram Yes.
The machine does the work instead of asking programmers to rearrange their code.
Your reminder reminds me of Holt’s Data Descriptors, which reminds me of Cordy’s Orthogonal Code Generator which reminds me of RTL (which is used in gcc).
{kind=link}
Thank you all, for your comments! I find the insightful criticism to be quite helpful.
Hoping to clarify some points:
- IMO The Ground Truth is Programming, not Code.
- IMO, change, even big change, is possible, especially in a young discipline like this. We are witnessing big change right now - the conversion of gasoline-powered automobiles to electric-powered automobiles. The enormous infrastructure for supplying gasoline is being replaced. The figurehead for this huge change believes in “First Principles Thinking” [fs.blog/first-principles]. Counter-arguments against big change might include:
- The fact that electric cars still have 4 wheels and still have offset steering wheels (instead of centered steering sticks as in the first automobile)
- The fact that the change-over from gas to electric is being facilitated by the existence of hybrid cars.
Computer keyboards are still QWERTY.
IMO, change is driven by perceived orders-of-magnitude improvement (in process? ... in what?). It remains incumbent on me to explain why I think that it is possible to improve on programming, noting that hardware has improved, and, noting that end-user apps have improved, while maintaining the assertion that programming languages have not improved proportionally.
- PEG blurs the line between characters in a Scanner vs. tokens in a Parser. IMO this is important and may lead to change.
- IMO, snipping ALL dependencies is important and may lead to change. Hence, this long response to an issue in an experimental code repo. To my eyes even simple
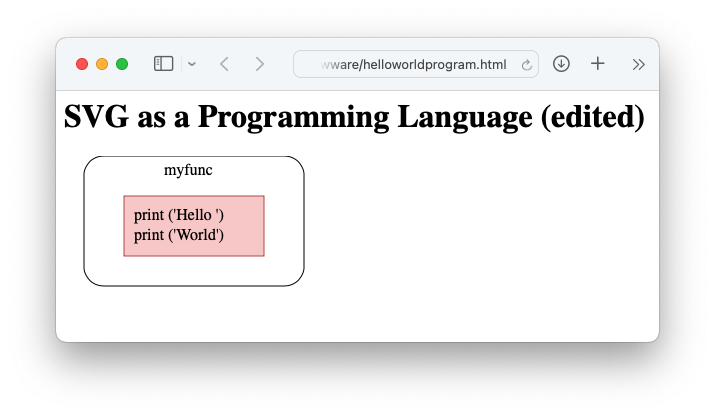
f(x)causes several kinds of dependencies that are ripe for snipping. - SVG. This is the simplest (albeit useless) example of SVG as a “programming language” that I could imagine. There’s more, and this is but a hint. This useless example transpiles a diagram to running Python code. The live code is at drawware.
github.com/guitarvydas/drawware/blob/dev/sourcecodehelloworld.png?raw=true
{kind=link}
<html>
<body>
<h1>My first SVG</h1>
<svg>
<g id='myfunc'>
<rect x="20" y="0" width="280" height="130" rx="19.5" ry="19.5" fill="none" stroke="black"/>
<text x="120" y="19">myfunc</text>
<g>
<rect x="60" y="40" width="200" height="60" fill="#f8cecc" stroke="#b85450"/>
<text x="70" y="64">print ('Hello ', end='')</text>
<text x="70" y="84">print ('World')</text>
</g>
</g>
</svg>
</body>
</html>the Ohm-JS grammar that I used is:
CodeDrawing {
Main = "<html>" "<body>" H1 Drawing "</body>" "</html>"
H1 = "<h1>" stuff "</h1>"
Drawing = "<svg" stuff ">" CodeContainer "</svg>"
CodeContainer = "<g" FunctionName ">" Boundary Title CodeBlock "</g>"
Boundary = "<rect" stuff "/>"
Title = "<text" stuff ">" name "</text>"
CodeBlock = "<g>" RedRect Text+ "</g>"
RedRect = "<rect" (~AttrRed any)* AttrRed stuff "/>"
FunctionName = "id=" sq name sq
Text = "<text" stuff ">" stuff "</text>"
AttrRed = "fill=" dq "#f8cecc" dq
stuff = notElementChar+
notElementChar = ~"<" ~">" ~"/>" any
name = letter alnum*
sq = "'"
dq = "\""
}And my personal notation (“Fab”) that completes the transpiler is:
CodeDrawing {
Main [khtml kbody H1 Drawing kbodyend khtmlend] = ‛«Drawing»'
H1 [kh1 stuff kh1end] = ‛«kh1»«stuff»«kh1end»'
Drawing [ksvg CodeContainer ksvgend] = ‛«CodeContainer»'
CodeContainer [kgroup FunctionName k Boundary Title CodeBlock kgroupend] = ‛def «FunctionName» ():«CodeBlock»
«FunctionName» ()'
Boundary [krect stuff kend] = ‛«krect»«stuff»«kend»'
Title [ktext stuff k name ktextend] = ‛«ktext»«stuff»«k»«name»«ktextend»'
CodeBlock [kgroup RedRect Texts+ kgroupend] = ‛\n(-«Texts»-)'
RedRect [krect cs* AttrRed stuff kend] = ‛«krect»«cs»«AttrRed»«stuff»«kend»'
FunctionName [kid sq1 name sq2] = ‛«name»'
Text [ktext stuff kend stuff2 ktextend] = ‛\n«stuff2»'
AttrRed [kfill dq kred dq2] = ‛«kfill»«dq»«kred»«dq2»'
stuff [cs+] = ‛«cs»'
notElementChar [c] = ‛«c»'
name [c1 cs*] = ‛«c1»«cs»'
sq [c] = ‛«c»'
dq [c] = ‛«c»'
}The generated Python code (from the diagram) is:
def myfunc ():
print ('Hello ', end='')
print ('World')
myfunc ()FYI - Fab transpiles to JavaScript code that can be used in conjunction with Ohm-JS. I got tired of writing JavaScript, so I built an SCN (nano-DSL) for myself.
I’ve chosen not to include the generated JavaScript code in this thread, but have pushed a working transpiler to the github listed above.
[pardon the cave-man HTML, but I don’t know enough about building web pages, and, clearly, need help]
31:50~ “In a ‘real’ Computer Science, the best languages of an era should serve as ’assembly code” for the next generation of expression.
youtube.com/watch?v=fhOHn9TClXY&t=859s
Alan Kay