Jim Meyer 2022-11-24 07:46:44 Vector-graphics used for design is stored in files and cloud databases, but that doesn't mean designers write text or SQL to interact with it. Code needs to be no different. It needs a UI.
Tudor Girba 2022-11-24 10:16:26 We can never perceive the inside of a system without an environment that presents it to us. That makes the environment essential. And so, the environment’s properties must be a core focus in software development, too.
Paul Tarvydas 2022-11-24 13:03:38 The way I see it, Code is a UI. It’s the 1950s solution to the problem of “how to replace this bank of toggle switches by something more flexible”. IMO, we need a new UI for programming, devised for computers and problems of 2022 (which, unlike computers of the 1950s, are distributed and no longer memory-constrained, etc.). I favour the idea of using SVG Elements, instead of Characters, in the design of 2022+ programming UXs.
Jim Meyer 2022-11-24 13:59:59 Paul Tarvydas Fully agree that we need more modern UIs for code! SVG sounds interesting as a UI for code. Any links/projects you can share?
Jim Meyer 2022-11-25 05:14:52 @Katie Bell Ah, nice, didn't catch that detail when I saw your talk a while back. Looks like you've pivoted away from JavaScript towards Python?
Jim Meyer 2022-11-25 05:16:23 What were the main reasons? Interested because we're going for TypeScript and React 😁
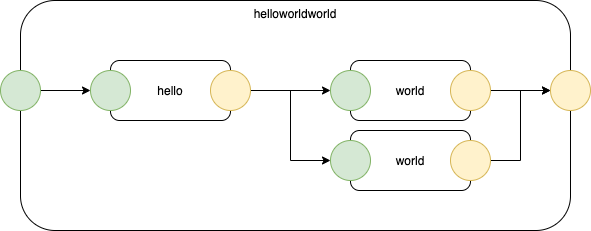
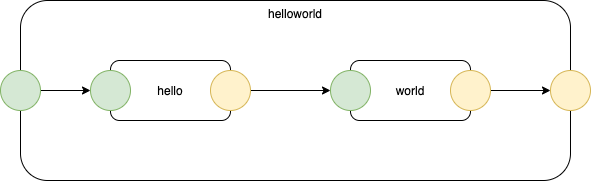
Paul Tarvydas 2022-11-25 06:44:34 I slapped together a Makefile that demonstrates a draw.io to .JSON transpiler. Draw.io is a lot like SVG - it’s a better technical diagram editor than anything I know of (suggestions welcome). Clone github.com/guitarvydas/eh and type ‘make’. This stuff is WIP and contains a bunch of other issues that interest me (0D, transpiling the generated .JSON to Python and to CL, incremental transpilation, synonyms, etc., etc.). ATM, only the build of helloworld.json works, and the rest of the build process breaks. Maybe I’ll fix the build script in the morning...
ATM, the code drops into PROLOG to infer semantic information about the diagram. I think that this can be done more simply, e.g. using Ohm-JS, but I haven’t done it (yet).
I wrote a bunch of point-form notes regarding AHAs w.r.t. DaS (Diagrams as Syntax) using SVG. If you find this interesting, the notes are at: publish.obsidian.md/programmingsimplicity/2022-11-24-Parsing+SVG+Languages
Katie Bell 2022-11-25 07:09:54 Jim Meyer When I was doing TypeScript/React there was a ton more syntax that I had to support, including HTML/CSS. Since I’m basically building each node of the AST, more syntax meant I couldn’t focus on the usability and editing experience. The plan is to go revisit TS/JS and HTML/CSS at a future date.
Jim Meyer 2022-11-25 08:10:45 @Katie Bell Got it 🙂 That makes a lot of sense for a structural editor, and for proving/refining the core editing experience. We're a visual editor with a canvas, so we're more at the "use React components like visual Lego blocks" at this stage, without us having gone into low-level/raw CSS.
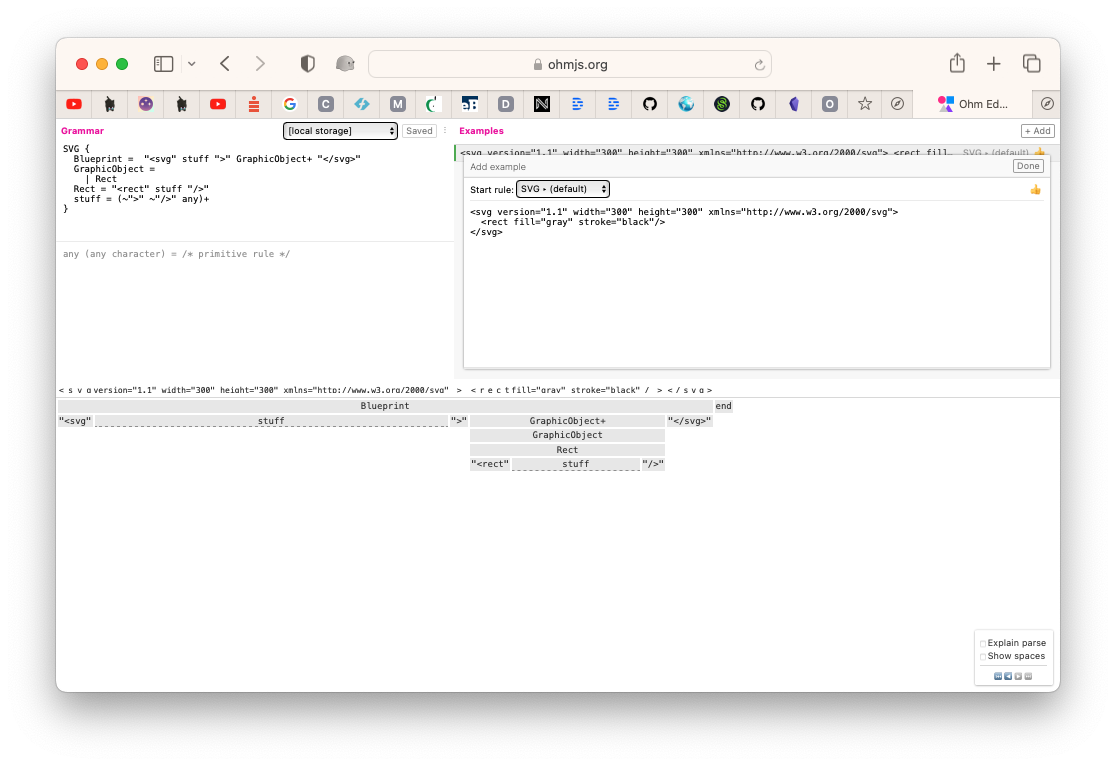
Paul Tarvydas 2022-11-25 14:15:23 Trimming most of the detail, here is a trivial example of an SVG file:
<svg version="1.1" width="300" height="300" xmlns="[w3.org/2000/svg](http://www.w3.org/2000/svg)">
<rect fill="gray" stroke="black"/>
</svg>
I’ve written a trivial parser in Ohm-JS:
SVG {
Blueprint = "<svg" stuff ">" GraphicObject+ "</svg>"
GraphicObject =
| Rect
Rect = "<rect" stuff "/>"
stuff = (~">" ~"/>" any)+
}
Paul Tarvydas 2022-11-25 14:17:04 The code is in my github svg
In my mind, SVG Elements are Atoms, and characters are but Quarks.
Ohm-JS insists on having me deal with Quarks. I use Ohm-JS to describe Atoms and to build Molecules out of Atoms. Molecules can then be used to define new programming languages.
Jim Meyer 2022-11-25 18:55:06 Are hyperlinks the biggest idea to arrive once we had computing?
I mean in terms of impact on our lives. On our future. A piece of transformative UX design and engineering work that was done—without any chance of knowing how massive it would become.
I think hyperlinks are bigger than the Internet. The Internet isn't the Internet without hyperlinks. Yes, hyperlinks don't work without a running internet, but the Internet isn't "the thing", it's "the thing that let us create the (many exciting) things".
It's wild to think that once the idea of hyperlinks formed, the UX design that arose was the application of text color and an underline. With that, semantic color and an underline, we got:
Hyperlinks as sharing.
Hyperlinks as social currency.
Hyperlinks as digital neural connections.
Hyperlinks as the connective tissue of civilization.
Hyperlinks as the most transformative tool in use by humans today?
Or maybe, just maybe, cats had this planned out all along 😁
Personal Dynamic Media 2022-11-25 19:51:26 "Hyperlinks as social currency" has a few big disadvantages.
It's remarkable how often people online don't link to those they are arguing against, or even give the name of the person or publication they're criticizing, because they don't want to "promote" the web site or account of their intellectual opponent.
This makes it difficult to follow many of the most important social dialogs in our culture, and makes it easy to commit straw man fallacies when one is concealing the original text being criticized.
Treating hyperlinks as social currency has also encouraged an explosion of link spam that has made search engines much less useful than they were 10-20 years ago.
Also, the epidemic of broken links means that knowledge keeps being lost at a frightening rate, which makes the shift away from paper dangerous because it so dramatically increases the danger of any given piece of knowledge being lost.
So yes, hyperlinks are awesome, but we haven't perfected them yet. Not by a long shot.
Jim Meyer 2022-11-25 21:33:41 @Personal Dynamic Media It's interesting how, with all the flaws and limitations of Hyperlinks 1.0, so much of the modern world relies on them. Seems like an example of "Worse is better" like with JavaScript. Type a string and you've got a link. Simple, yet imperfect, 50% of the time it works every time. A "better" solution is likely much more complicated, maybe 10X, which hinders adoption and "I just created a link using Notepad" kinds of UX.
How would Hyperlinks 2.0 work? How much of the internet and other enabling technologies would have to change and be improved?
A few things that came to mind as I read your comment:
- Semantics for a link, e.g. to enable links with semantics such as "counter argument" instead of blindly being "social currency". Maybe the identity of the linker needs improvements as well.
- Versioning/snapshotting of linked-to resource to prevent dead links, but how to reconcile that with the distributed nature of the Internet and dynamic pages?
A lot of added complexity, which makes it interesting to think about, but also super challenging in terms of what the adoption story looks like.
Duncan Cragg 2022-11-25 23:38:14 I agree. Links are so powerful, so empowering to people, that companies like Facebook try their best to suppress them. The so-called "Web" standards have been subverted by this movement to focus on "APIs" at the expense of the loss of what made the Web great in the first place.
Personal Dynamic Media 2022-11-25 23:54:59 I think Ted Nelson describes a lot of good ideas in Literary Machines, but his vision was too centralized.
I suspect something like Xanadu built on something like IPFS would be a good starting point, but it would require the ability to index documents not just by their own hashes, but also by the hashes of files for which they describe links and files for which they contain updates. It would also require some ability to filter search results by author or publisher so you can see updates from just the original author, or links just from sources you're interested in.
I'm not sure if that's the right answer or even close, but I think Nelson did a good job of articulating the capabilities we should be trying to provide.
Lorand Kedves 2022-11-26 05:06:17 Interesting discussion, I would add a few notes.
- The greatest human minds invented informatics to allow them parallel interaction with shared knowledge. They knew that knowledge is a dynamic semantic network and network is a set of nodes interconnected by links. So of course yes, links are hyper... important 🙂 See also, As we may think (Vannevar Bush, 1945). A practical implementation of such a system was NLS created by Douglas Engelbart, who spent decades on trying and failing to explain what it means for any human organisation.
- The focus moved towards text-oriented environments because it was easier to explain and measure (also because it separated the syntax from the model it describes, but that's another story). So, instead of working on shared mutable networks (that is knowledge), we turned to texts (a serialized, final form of a current knowledge) that can refer to other texts. The competing ideas of referring were Dr. Ted Nelson's transclusion in Xanadu and Sir Tim Berners-Lee's implementation of hyperlinks. The second was simpler and more acceptable by business that could not handle transcopyright, so it became the de facto standard. The much better Xanadu failed for 50 years because it contains three fundamental flaws, ironically the cure was there in Dr. Nelson's other idea, the Zigzag database all the time (but that's another story).
- As a conclusion, the current thinking of links is that they point to, and sometimes into a stream. If you see it written in a sentence, it tells you why it does not work: this approach can't handle changes and versioning. That requires an opposite approach, accepting that knowledge is a constantly changing network of which we create persistent snapshots and through the links you must be able to see the momentary state and navigate through the changes. Of course, this is much more complicated than books, this is why computers are still just paper-simulators - but Dr. Nelson is much better at explaining it. Those damned cats!
That's my (bit more than) 2 cents.
Lorand Kedves 2022-11-26 06:01:31 Sorry, forgot to call out the difference: transclusion reflects the perspective of the author (build hypertext from the sources) while hyperlinks are for the reader (consume hypertext, look up the background only if interested). By definition, the second is more popular but at the same time much less reliable... Or in other words: Xanadu would support the hard work of learning and contributing to our common improvement, while the current hypermedia supports acting smart, "creating popular content". See also, Amusing Ourselves to Death by Neil Postman if you are serious, or Idiocracy if you can handle massive sarcasm... 🙂
That's why I said Xanadu was better (though still not Memex/CoDIAK).
Duncan Cragg 2022-11-27 11:44:18 I think we can put Xanadu to rest, to be honest. It ain't happenin'. But we can take some juicy bits from it:
- linking to either a snapshot static version or to the latest version
- transclusion
Duncan Cragg 2022-11-27 11:46:44 And add
- everyone is first class, so we own our own content and identity
- the latest version mentioned above gets pushed to you when it changes
- not just paragraphs of text or images to transclude, but entire docs, todo lists, calendar events, 3D models, whatever
Duncan Cragg 2022-11-27 11:48:07 Obvs you need non-source cacheing of intermediate static versions (you can't trust the source not to wipe out the history too) which combined with people being first class means we're now building a P2P network, but we can't use IPFS, etc cos we need content updates
Duncan Cragg 2022-11-28 11:56:25 Your 1, 2 and 3 seem fine to me, not sure where the disagreement is there. #1 seems interesting not boring, but it has to be open, yes. I'm not interested myself in deep document stuff other than the base idea of keeping the structure in a more "data" state, with trees, versions, transclusions etc. I'm more interested in expanding to other types, such as (lower level) 3D and (higher level) semantics/data - well, calendar events, social networks, etc.
I'm 58 and have a lot of free time currently to work on this stuff, so I'm both better and worse off than you!
What deep water? What proper gear? What Turing/state machine content are you referring to?
Duncan Cragg 2022-11-29 20:00:39
Deep water: if you move away from text (where the language is external to the content) towards direct symbol manipulation through object networks, you enter the realm of forgotten heroes who have already done a lot.
Please be specific - Who? What?
... those heroes and their results, giving the theoretical explanation of my experience ... brought the understanding why I can't explain it so I gave up trying... why it was horribly wrong....
Please do elaborate on these points!
Duncan Cragg 2022-11-30 08:44:31 I'm finding this exchange rather frustrating. Does anyone else here on this thread have anything to add or offer?
Konrad Hinsen 2022-11-30 10:36:24 Interesting discussion, though I have the impression that everyone gives a different meaning to "link", leading to serious misunderstandings.
In a way, that's a symptom of the mess that the tech world has become. As @Lorand Kedves nicely summarizes in the beginning of his "science of being wrong".
My analysis of this mess is "too much interaction". If you look back at the history of technology, on a century-to-millenium timescale, it has relied on a equilibrium of tinkerers, scientists, and engineers all taking inspiration from each other but mostly working according to their own logics, solving the problems they most care about. In today's tech world, tinkerers dominate so much that scientists and engineers can no longer do their long-term work of identifying fundamental concepts and principles and of developing mature technologies. The tinkerer's ecosystem churn and low-reliability products are not a solid basis to build on, and require so much attention just to keep running that society has no attention (and resources) left for long-term study and design.
Perhaps someone somewhere is working on ideas like Xanadu, but if that someone is actually productive, they have isolated themselves so much from our tech world that we are unlikely to ever hear from them.
Konrad Hinsen 2022-11-30 10:46:55 In this discussion, we have the HTML link as the tinkerer's view, Xanadu as the engineer's view, and relations (as in "relational database") as the scientist's view. What we'd need is the three points of view being improved iteratively, learning from each other.
Nicholas Yang 2022-11-26 21:00:52 Jack Rusher 2022-11-27 09:25:45 There's good and bad here. I like that you talk about incremental/error tolerant aspects of things, as these are very much required to build good tooling. OTOH:
- the bit about language servers seems to come from the perspective that they're a good thing when they're really just a gnarly patch for languages that don't support interactive development
- Treesitter generating C is one of the good things about it, as the C ABI is a sort of lingua franca on the operating systems we have available
- You'll need to explain your pushback against (for example) bison and Racket in more detail to be taken seriously, it's currently just handwaving
Nicholas Yang 2022-11-29 20:04:49 Thanks for the feedback! I’d have to politely disagree about the point on language servers. I’ve tried interactive development and I think it’s a valid set of tradeoffs but not my personal cup of tea.
Tree sitter generating C is probably the right call, but I would be interested to see if generating Rust or Zig would be worthwhile, as you could keep the C ABI but make the build process way way easier. I’ve been trying to compile a rust codebase with tree-sitter to wasm and because of the C code, I can’t compile to wasm32-wasi without some messy patching, and wasm32-unknown-emscripten appears to be going out of date and has ABI incompatibilities with Rust compiled to wasm. If tree-sitter could generate rust it’d make the composability a lot nicer.
As for your last point, yeah fair. I’ll try to come up with good examples. Bison has quite poor documentation and an extremely poor dev experience but you’re right, I need to iron that out concretely. Racket is almost worth an entire blog post on its own. I like it a lot but it’s kind of too large and encompassing of an ecosystem to simply be a tool inside a compiler. You either use racket or you don’t.
Thanks again!
Jack Rusher 2022-11-30 11:14:48 I'd be interested in hearing a bit about your experiences with interactive development! 🫖
{kind=link}
{kind=link}
{kind=link}