I think it is, yeah. It really seems so darn trivial, but I just… can’t get it! Let me type it out, and if it’s helpful, I can upload some of the sketches I have trying to break it down. So, here’s the gist:
Keywords: Texture / glyph atlas, macOS, Swift, Metal, iOS, vector space transforms
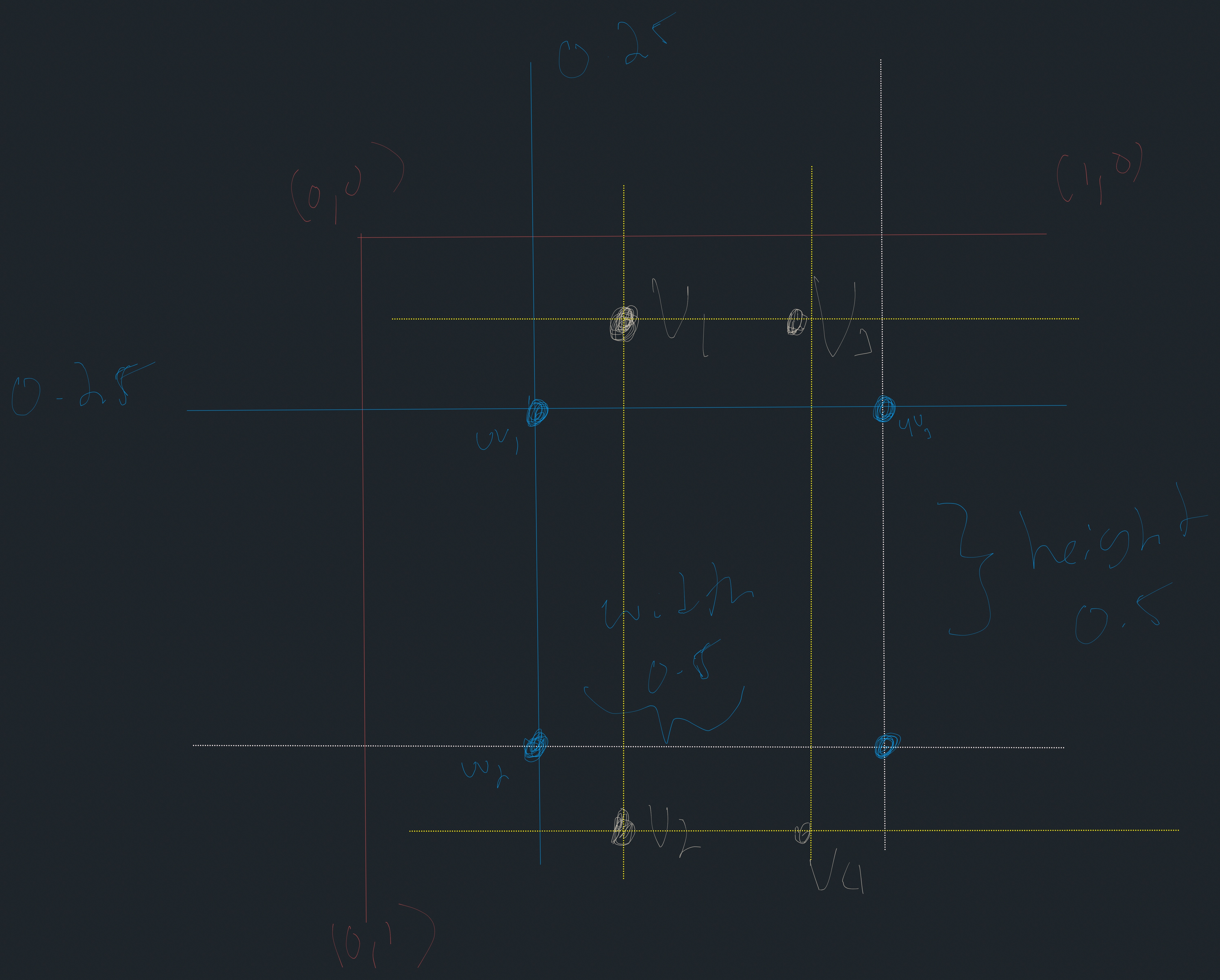
Given: I’ve got a set of “vertices” (x, y) in normalized space, from (-1, 1) on the domain and range. Just a simple cartesian space. I’ve also got a set of “texture coordinates” (u, v), which instead map to (0, 1) on the domain and range, with (0, 1) on the range an x-axis flip. This is apparently really common, and it’s the way the Metal shading language defines its coordinate spaces.
I also know how to convert from vertex-space to uv-space:
u = (x + 1) / 2
v = -(y - 1) / 2
Also given: I have a texture in UV space where I want to define arbitrary rectangles. These rectangles are glyph-stamps in the [(0,1), (0,1)] bounding box range. These are easily computed given the full size of the texture I am creating rectangles from.
The problem: I have a single set of vertices that define a quad. Top left / right, bottom left / right. These are always centered around the origin. Meaning, I can have a square that fills the vector space with these coordinates:
(-1, 1)
(-1, -1)
( 1, 1)
( 1, -1)
Assume we will “resize” those in some way by symmetrically bringing in the sides as needed - again, all around the origin.
Given that I have those precomputed coordinates above which map to UV space, how do I take those arbitrary vertices in vertex space and map them to the ‘rectangular sections’ of uv-space?
{kind=link}